



Multiple Linear Regression
What is Multiple Linear Regression?
Multiple linear regression is a statistical technique to model the relationship between one dependent variable and two or more independent variables by fitting the data set into a linear equation.
The difference between simple linear regression and multiple linear regression:
[unordered_list style=”star”]
- Simple linear regression only has one predictor.
- Multiple linear regression has two or more predictors.
[/unordered_list]
Multiple Linear Regression Equation
![]()
Where:
[unordered_list style=”star”]
- Y is the dependent variable (response)
- X1, X2 . . . Xp are the independent variables (predictors). There are p predictors in total
[/unordered_list]
Both dependent and independent variables are continuous.
[unordered_list style=”star”]
- β is the intercept indicating the Y value when all the predictors are zeros
- α1, α2 . . . αp are the coefficients of predictors. They reflect the contribution of each independent variable in predicting the dependent variable.
- e is the residual term indicating the difference between the actual and the fitted response value.
[/unordered_list]
Use SigmaXL to Run a Multiple Linear Regression
Case study: We want to see whether the scores in exam one, two, and three have any statistically significant relationship with the score in final exam. If so, how are they related to final exam score? Can we use the scores in exam one, two, and three to predict the score in final exam?
Data File: “Multiple Linear Regression” tab in “Sample Data.xlsx.”
Step 1: Determine the dependent and independent variables, all should be continuous. Y (dependent variable) is the score of final exam. X1, X2, and X3 (independent variables) are the scores of exam one, two, and three respectively. All x variables are continuous.
Step 2: Start building the multiple linear regression model
- Select the range of independent and dependent variables in Excel.
- Click SigmaXL -> Statistical Tools -> Regression -> Multiple Regression
- A new window named “Multiple Regression” pops up and the selected range appears automatically in the box below “Please select your data”
- Click “Next >>”
- A new window also named “Multiple Regression” pops up
- Select “FINAL” as “Numeric Response (Y)” and “EXAM1”, “EXAM2” and “EXAM3” as “Continuous Predictor (X)”
- Click “OK>>”
- The regression analysis results appear in the newly generated spreadsheet “Multiple Regression” and the residual analysis results appear in another new spreadsheet “Mult Reg Residuals (1)”.
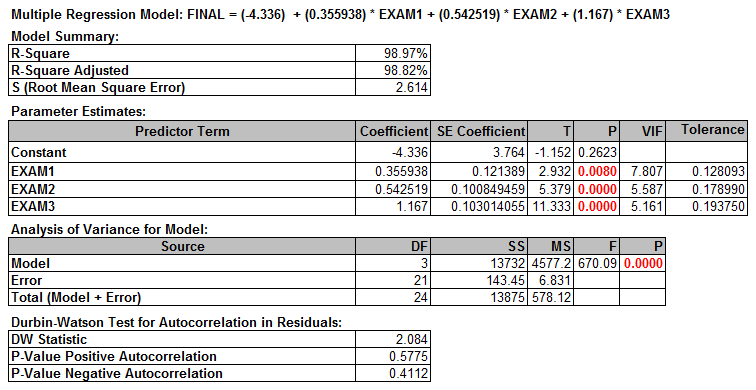
Step 3: Check whether the whole model is statistically significant. If not, we need to re-examine the predictors or look for new predictors before continuing.
 [unordered_list style=”star”]
[unordered_list style=”star”]
- H0: The model is not statistically significant (i.e., all the parameters of predictors are not significantly different from zeros).
- H1: The model is statistically significant (i.e., at least one predictor parameter is significantly different from zero).
[/unordered_list]
In this example, p-value is much smaller than alpha level (0.05), hence we reject the null hypothesis; the model is statistically significant.
Step 4: Check whether multicollinearity exists in the model.
The VIF information is automatically generated in table of parameter estimates.
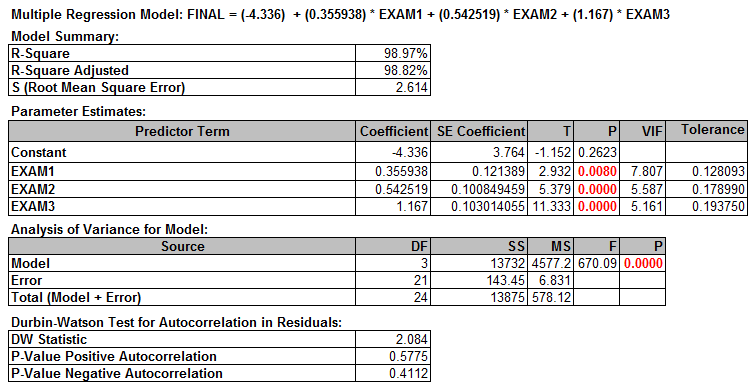 We use the VIF (Variance Inflation Factor) to determine if multicollinearity exists.
We use the VIF (Variance Inflation Factor) to determine if multicollinearity exists.
Multicollinearity
Multicollinearity is the situation when two or more independent variables in a multiple regression model are correlated with each other. Although multicollinearity does not necessarily reduce the predictability for the model as a whole, it may mislead the calculation for individual independent variables. To detect multicollinearity, we use VIF (Variance Inflation Factor) to quantify its severity in the model.
Variance Inflation Factor (1)
VIF quantifies the degree of multicollinearity for each individual independent variable in the model.
VIF calculation:
Assume we are building a multiple linear regression model using p predictors.
Two steps are needed to calculate VIF for X1.
Step 1: Build a multiple linear regression model for X1 by using X2, X3 . . . Xp as predictors.
Step 2: Use the R2 generated by the linear model in step 1 to calculate the VIF for X1.
Apply the same methods to obtain the VIFs for other Xs. The VIF value ranges from one to positive infinity.
Variance Inflation Factor (2)
Rules of thumb to analyze variance inflation factor (VIF):
[unordered_list style=”star”]
- If VIF = 1, there is no multicollinearity.
- If 1 < VIF < 5, there is small multicollinearity.
- If VIF ≥ 5, there is medium multicollinearity.
- If VIF ≥ 10, there is large multicollinearity.
[/unordered_list]
How to Deal with Multicollinearity
- Increase the sample size.
- Collect samples with a broader range for some predictors.
- Remove the variable with high multicollinearity and high p-value.
- Remove variables that are included more than once.
- Combine correlated variables to create a new one.
In this section, we will focus on removing variables with high VIF and high p-value.
Step 3: Deal with multicollinearity:
- Identify a list of independent variables with VIF higher than 5. If no variable has VIF higher than 5, go to Step 6 directly.
- Among variables identified in Step 5.1, remove the one with the highest p-value.
- Run the model again, check the VIFs and repeat Step 5.1.
Note: we only remove one independent variable at a time.
In this example, all three predictors have VIF higher than 5. Among them, EXAM1 has the highest p-value. We will remove EXAM1 from the equation and run the model again.
Run the new multiple linear regression with only two predictors (i.e., EXAM2 and EXAM3).
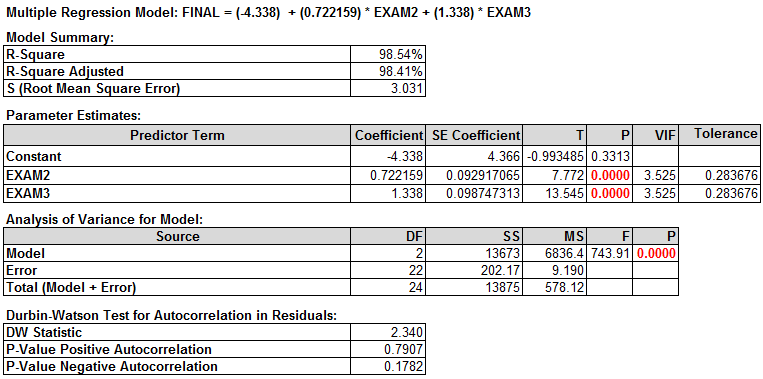
 Check the VIFs of EXAM2 AND EXAM3. They are both smaller than 5; hence, there is little multicollinearity existing in the model.
Check the VIFs of EXAM2 AND EXAM3. They are both smaller than 5; hence, there is little multicollinearity existing in the model.
 Step 4: Identify the statistically insignificant predictors. Remove one insignificant predictor at a time and run the model again. Repeat this step until all the predictors in the model are statistically significant.
Step 4: Identify the statistically insignificant predictors. Remove one insignificant predictor at a time and run the model again. Repeat this step until all the predictors in the model are statistically significant.
Insignificant predictors are the ones with p-value higher than alpha level (0.05). When p > alpha level, we fail to reject the null hypothesis; the predictor is not significant.
[unordered_list style=”star”]
- H0: The predictor is not statistically significant.
- H1: The predictor is statistically significant.
[/unordered_list]
As long as the p-value is greater than 0.05, remove the insignificant variables one at a time in the order of the highest p-value. Once one insignificant variable is eliminated from the model, we need to run the model again to obtain new p-values for other predictors left in the new model. In this example, both predictors’ p-values are smaller than alpha level (0.05). As a result, we do not need to eliminate any variables from the model.
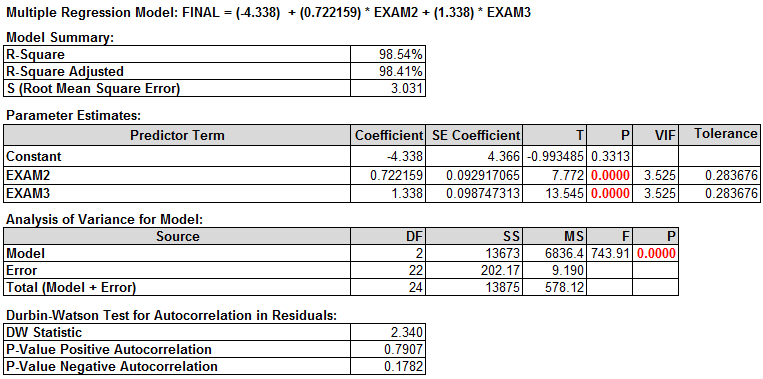 Step 5: Interpret the regression equation
Step 5: Interpret the regression equation
The multiple linear regression equation appears automatically at the top of the session window. “Parameter Estimates” section provides the estimates of parameters in the linear regression equation. Now that we have removed multicollinearity and all of the insignificant predictors, we have the parameters for the regression equation.
Interpreting the Results
Rsquare Adj = 98.4%
[unordered_list style=”star”]
- 98% of the variation in FINAL can be explained by the predictor variables EXAM2 & EXAM3.
[/unordered_list]
P-value of the F-test = 0.000
[unordered_list style=”star”]
- We have a statistically significant model.
[/unordered_list]
Variables p-value:
[unordered_list style=”star”]
- Both are significant (less than 0.05).
[/unordered_list]
VIF
[unordered_list style=”star”]
- EXAM2 and EXAM3 are both below 5; we’re in good shape!
[/unordered_list]
Equation: −4.34 + 0.722*EXAM2 + 1.34*EXAM3
[unordered_list style=”star”]
- −4.34 is the Y intercept, all equations will start with −4.34.
- 722 is the EXAM2 coefficient; multiply it by EXAM2 score.
- 34 is the EXAM3 coefficient; multiply it by EXAM3 score.
[/unordered_list]
Let us say you are the professor again, and this time you want to use your prediction equation to estimate what one of your students might get on their final exam.
Assume the following:
[unordered_list style=”star”]
- Exam 2 results were: 84
- Exam 3 results were: 102
[/unordered_list]
Use your equation: −4.34 + 0.722*EXAM2 + 1.34*EXAM3
Predict your student’s final exam score:
−4.34 + (0.722*84) + (1.34*102) =−4.34 + 60.648 + 136.68 = 192.988
Model summary: Nice work again! Now you can use your “magic” as the smart and efficient professor and allocate your time to other students because this one projects to perform much better than the average score of 162. Now that we know that exams two and three are statistically significant predictors, we can plug them into the regression equation to predict the results of the final exam for any student.